Self Hosting an LLM
Updated: 2026-01-15 18:58
Cloud-based AI is fast, but it comes at the cost of your data privacy and a monthly subscription fee. I decided to bring my AI home.
Using a compact HP EliteDesk and Kubernetes (K3s), I’m self-hosting the Llama 3.1 8B model. My setup is 100% private, runs entirely on my own hardware, and costs nothing to query (outside electricity). Here is the manifest, the performance benchmarks, and why the trade-off in speed is worth the total control.
The specifications of my home server are as follows:
HP EliteDesk 800 G3 Mini
Intel i5-6500T multimedia PC
32 GB RAM
1 TB 4-thread SSD
2.5 GHz
Hosting
Here is the manifest I'm using.
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama-llama8b
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
command: ["/bin/sh", "-c"]
args:
- "ollama serve & sleep 10; ollama pull llama3.1:8b; wait"
ports:
- containerPort: 11434
volumeMounts:
- name: ollama-storage
mountPath: /root/.ollama
volumes:
- name: ollama-storage
hostPath:
path: /home/hampus/k3s/ollama-data
type: DirectoryOrCreate
---
apiVersion: v1
kind: Service
metadata:
name: ollama-service
namespace: default
spec:
selector:
app: ollama
ports:
- protocol: TCP
port: 11434
targetPort: 11434
type: LoadBalancer
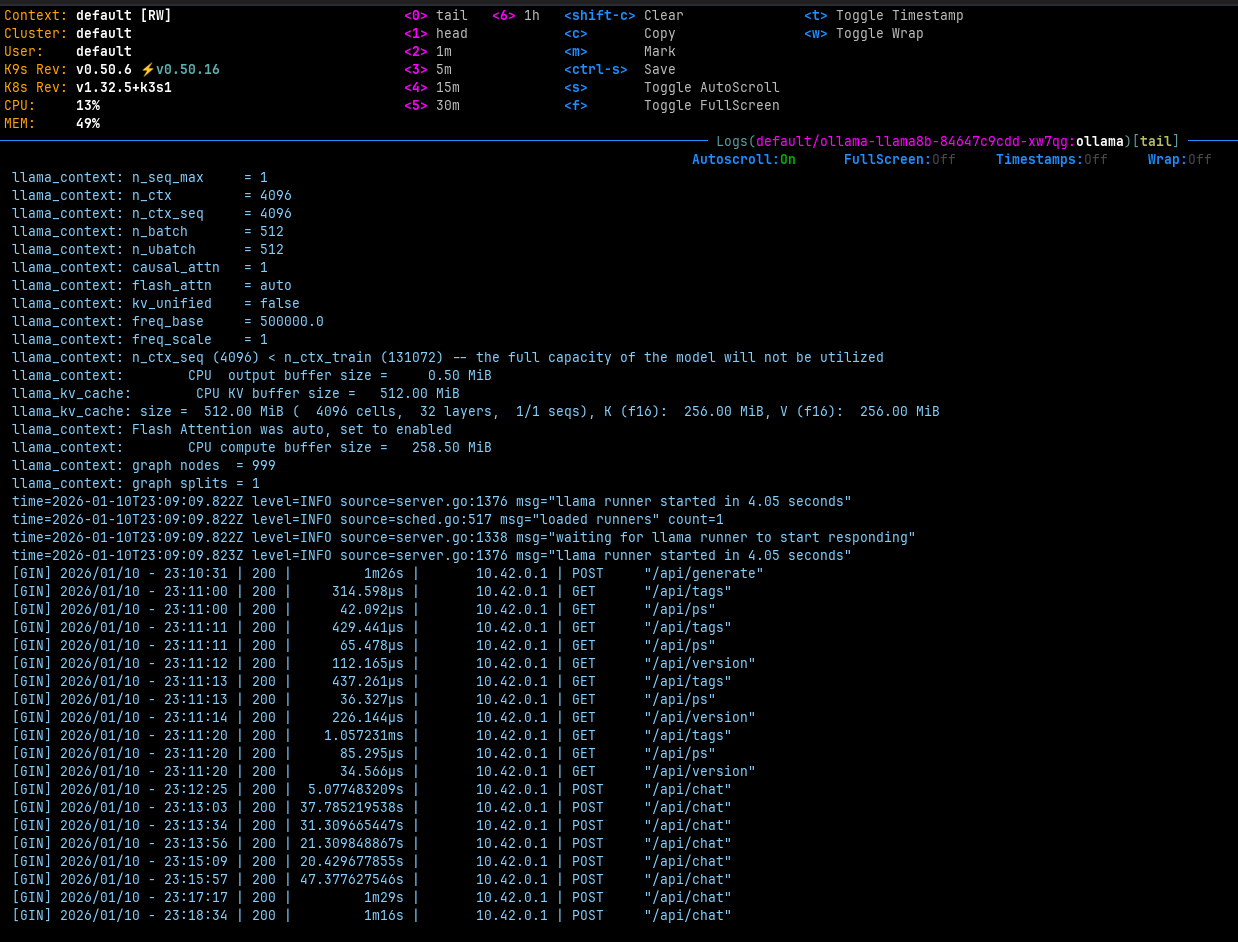
System Load
Resources

Prompting the model quickly leads to 100% CPU utilization across my four cores.
The 5GB of memory used is negligible since I have 32GB available.
Moreover, if the model is not queried within 5 minutes, it will offload the in-memory part to disk, thereby freeing up RAM.
It takes approximately 5 seconds for Llama to be ready on a cold start.
time=2026-01-10T23:27:15.443Z level=INFO source=server.go:1376 msg=
"llama runner started in 4.80 seconds"
Testing the Model
I'm currently hosting Open WebUI with several models: ChatGPT, Gemini, and now Llama8B. I've compared their performance to that of GPT-4.
Prompting and Comparing
Create a function in Python that:
takes two integer arguments and
multiplies them, returning the result.
Result
def multiply_two_numbers(num1, num2):
return num1 * num2
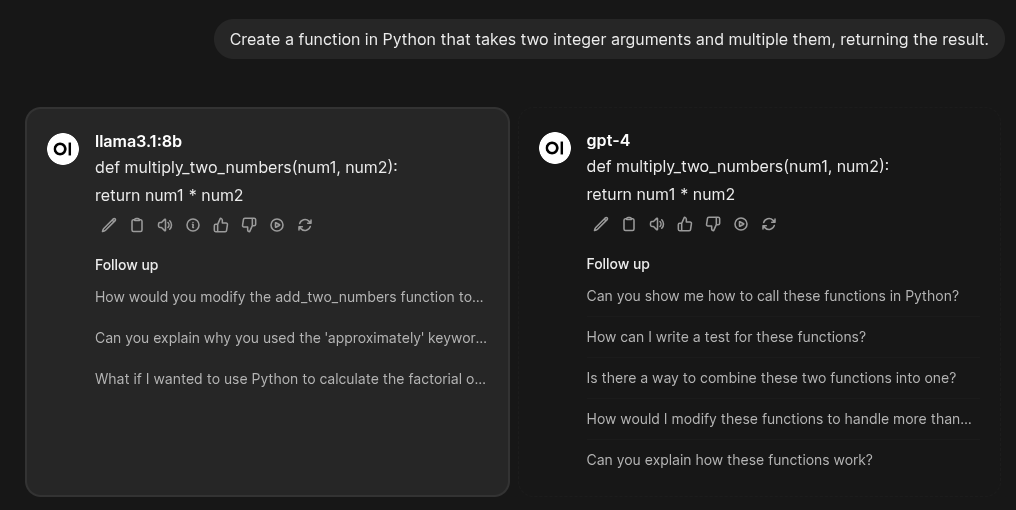
Answering a question on a link
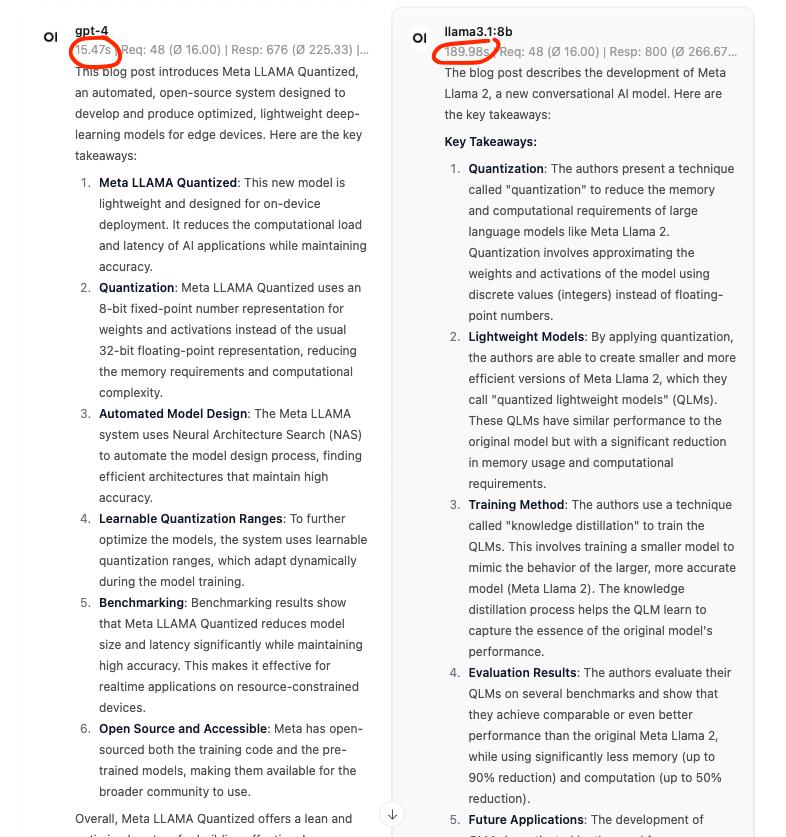
This took a staggering 1125% longer than chatGPT.
| ChatGPT 4 | Llama3.1 8B |
|---|---|
| 15.47 sec | 189.98 sec |
Latency
The comparison is striking. GPT-4 responded almost instantly, typically within a few seconds, whereas Llama took about 51 seconds to respond. This delay is expected since I'm operating it on a small home server without a GPU.
Summary
It is quite simple and entirely doable to self host a small LLM.
The performance of the local 8B model is impressive, particularly when compared to my previous experiences with a 2B model, which were underwhelming. This time, I posed three relatively simple questions, and the model handled them effortlessly:
- Create a simple function
- Suggest alternative keyboard layouts to Colemak
- Improve and correct this text as an editor with additional instructions